

Who Are You?!?!
Identifying and linking data records to the exact person or organization across multiple data sources is HARD and time-consuming. However, entity resolution is central to both business operations and security. So how do we solve this, especially at scale?
Data, Information, & Intelligence Relationship
At Prae, as former Intelligence Officers, we LOVE the simplicity of the Joint Intelligence / Joint Publication 2.0 Intelligence Model. This model is the core of our philosophy and technical approach.
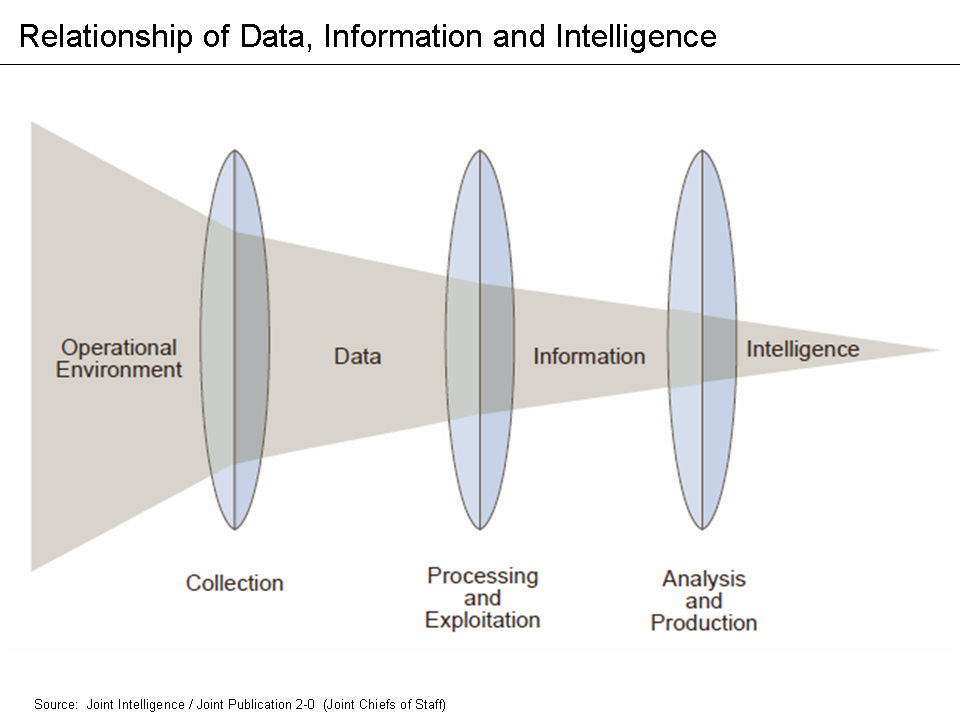
Here, our operational environment is the public domain where data is either voluntarily disclosed publicly (e.g. social media posts) or is legally accessibly by anyone (e.g. public court or property records). These observations and records are collected as data, processed into information, and analyzed for intelligence. The end goal is to produce intelligence, which can be actioned to help manage risk. Now let’s dive deeper into the technology…

Data Engineering & ETL
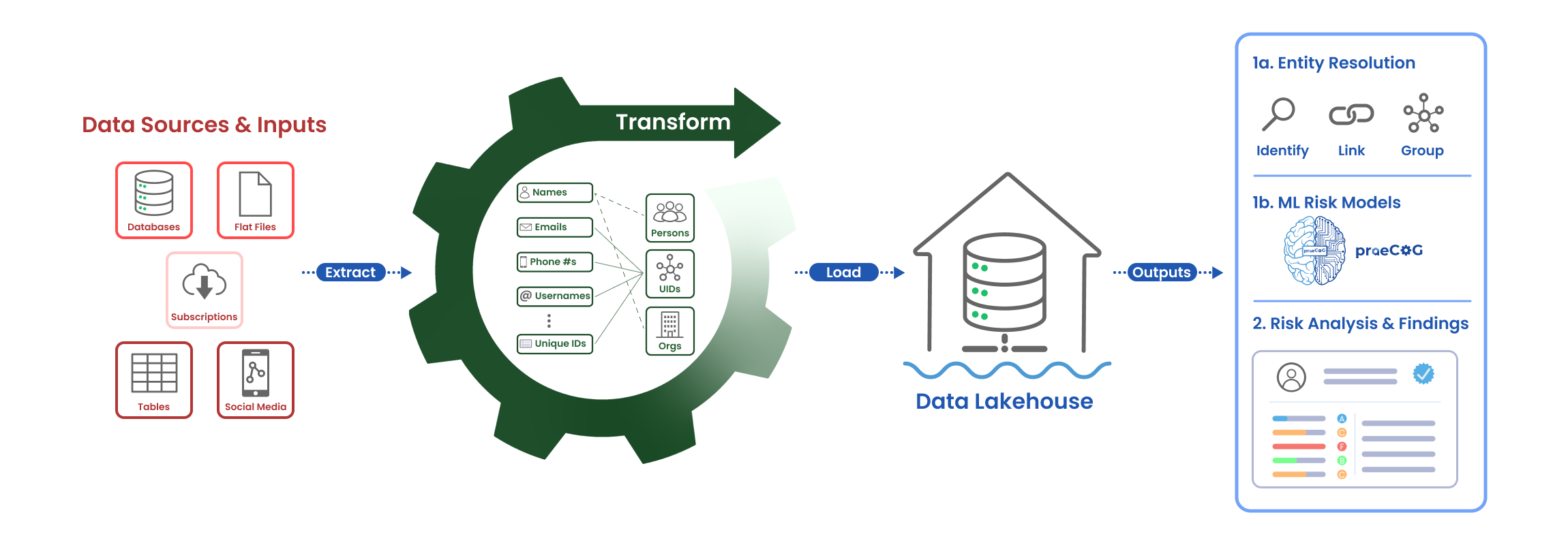
In order to tackle both the volume and complexity in the processing and exploitation of publicly available information (PAI), we designed an architecture to process PAI at scale with repeatable and predictable results.
Step 1: Defining Data Sources & Inputs
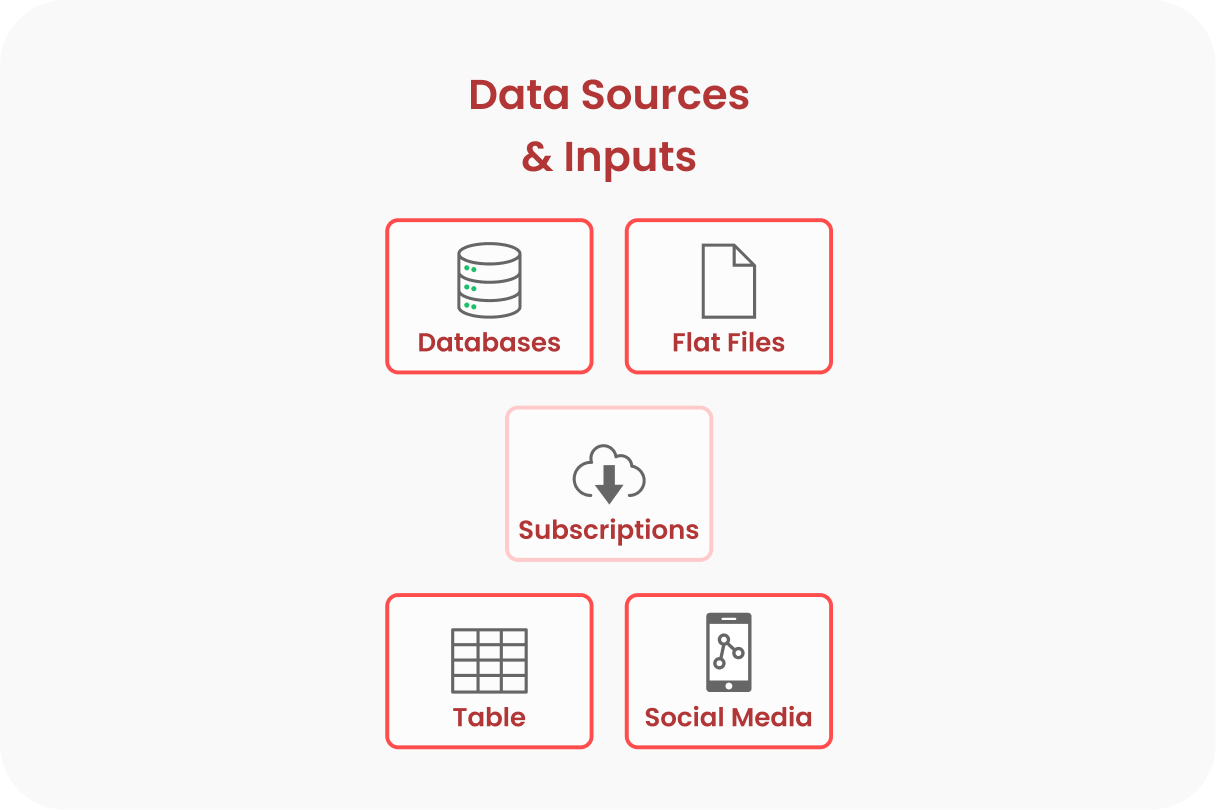
Data sources are ingested and stored in alignment with the medallion architecture: Bronze, Silver, and Gold. Data is also organized by the type of collection operations: opportunistic (highlighted in red), hybrid (highlighted in pink), and targeted (highlighted in dark red).
Step 2: Extracting Metadata & UIDs
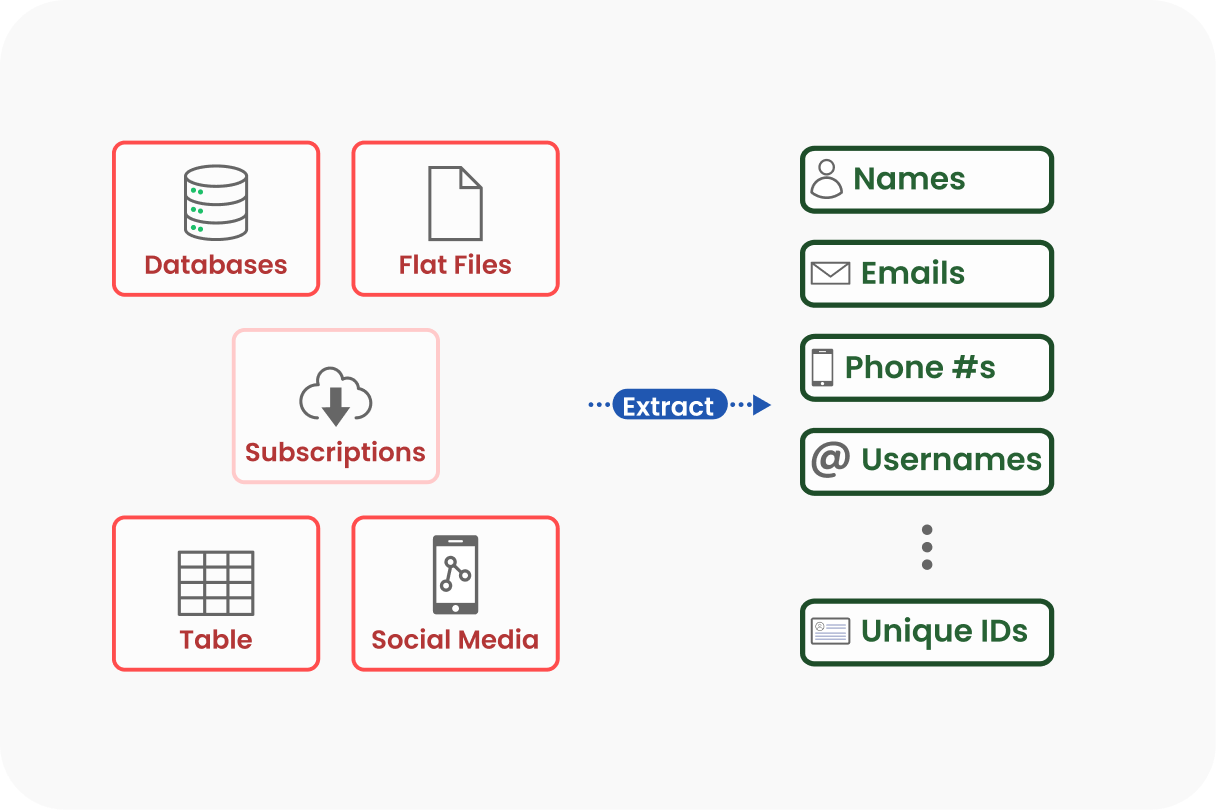
Raw data is lightly processed and staged in Bronze for pickup by our ETL architecture. Automated bulk extraction of metadata and any relevant unique identifiers (UIDs) gets stored in Silver.
Step 3: Transforming Data to Information
All data is transformed into Apache Parquet files and wrapped by Databricks Delta. Then we transform each of the 174x UUIDs into our proprietary entity schema, ontology model, and its appropriate Delta Table. Strings resembling a name convert to an entity. Similarly, strings, numbers, and symbols such as emails, phone numbers, usernames, etc convert to UIDs.
Step 4: Loading into a Data Lakehouse
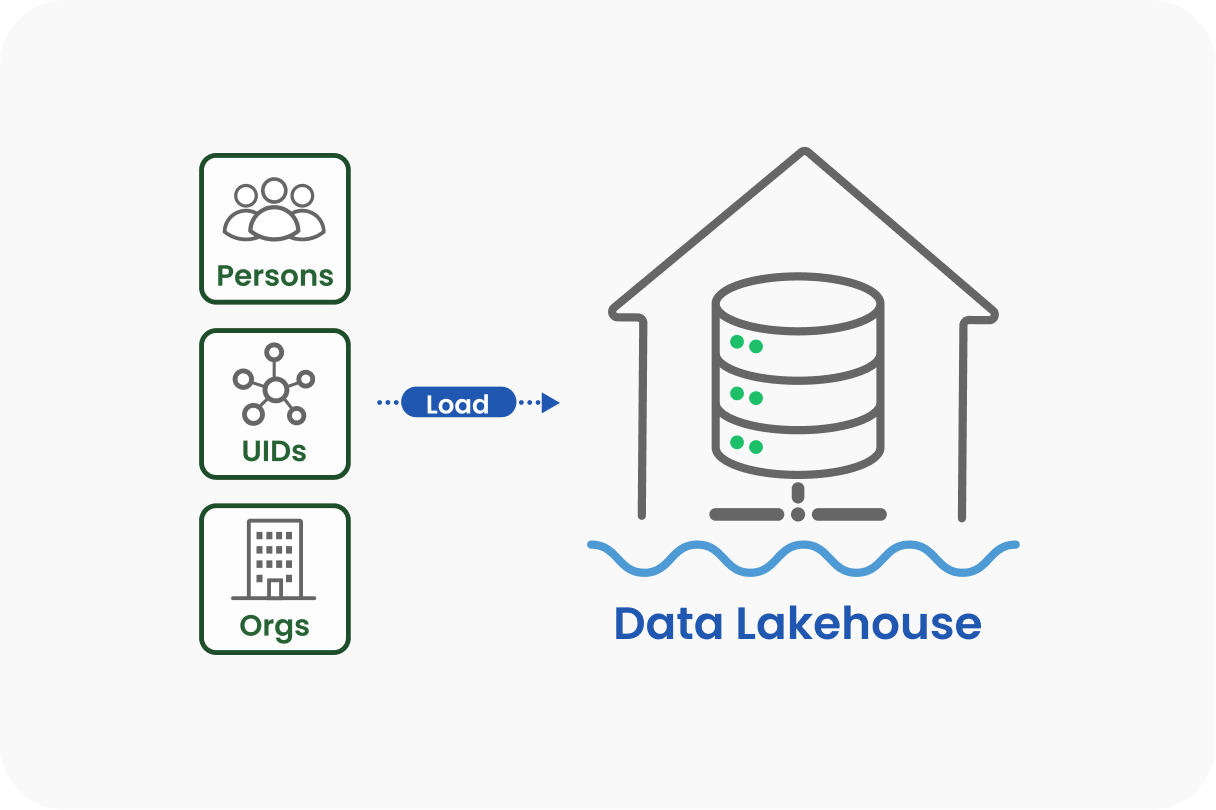
Processed data is loaded into Gold our analysts, machine learning (ML) models, and customers to consume and interpret. For this, we leverage a Data Lakehouse, which inherently provides a few key technology advancements and advantages.
Step 5: Intelligence for E&A and Actioning
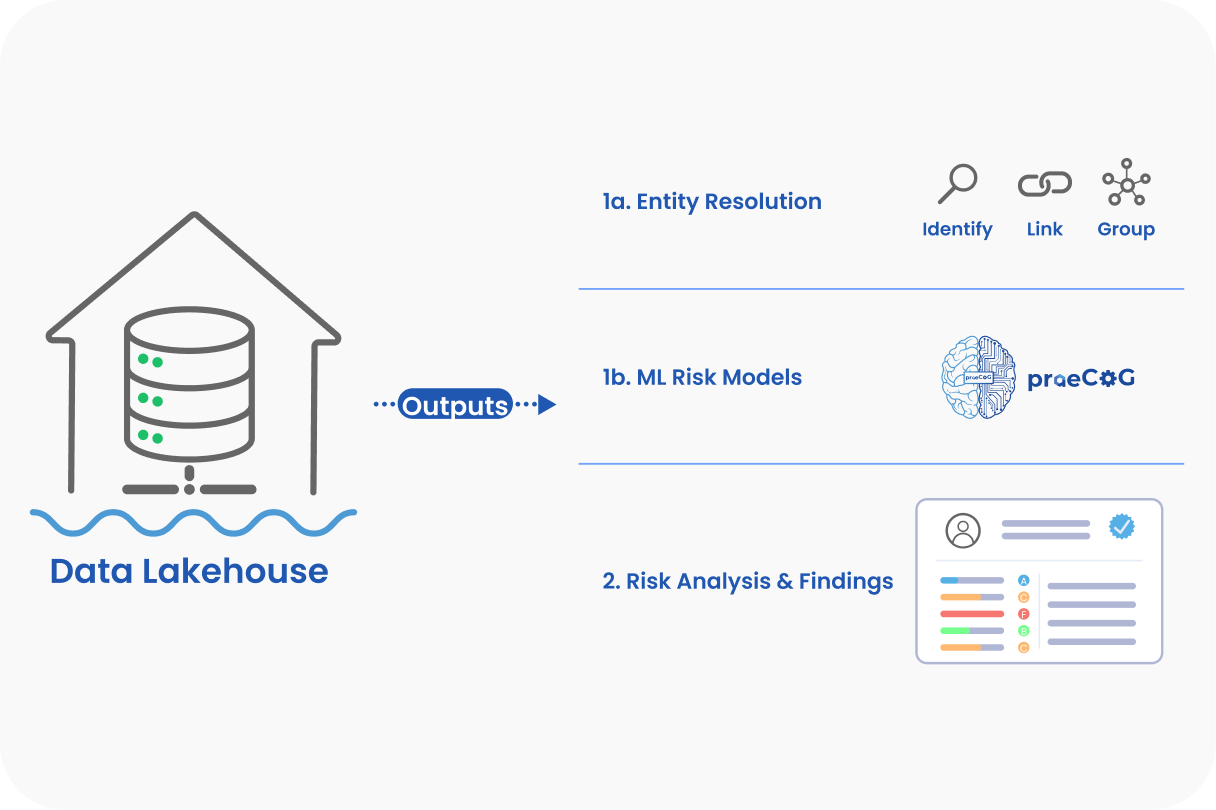
Intelligence is generated and delivered to the consumer for actioning and risk management. Unlike other platforms that are either single domain or static, we are the ONLY platform for continuous, cross-domain risks: physical, cyber, and psychological.
Key Products
Due Diligence

Enhanced Background Checks, M&As, Know-Your-Customer
Investigations

Cyber Counterintelligence, Insider Threat, Human Resources
Overwatch

Board of Directors, Executives, and Key Personnel