
Distilling Whisky & Data Engineering for Best Results

Suntory Hibiki 30Data engineering and data science are terms often conflated and used interchangeably with one another. The former is the scientific process of collecting, orchestrating, and processing data whereas the latter is the art of applying and interpreting analytic techniques. To create a parallel, data engineering is to whisky distillation as data science is to whisky aging/blending.
So what do whisky distillation and data engineering have in common?!?! The former is deeply rooted in tradition and craftsmanship whereas the latter is a Science, Technology, Engineering, & Math (STEM) discipline. In the first of our mashup blogs, we will explore the surprising parallel sciences of both and hopefully leave you with a greater appreciation for each. But first…why (am I writing this blog article)? In my last job/role, I saw and experienced firsthand the applicability of the intelligence (cycle or) process (Joint Publication 2-0) to private industry. Unfortunately, there was a general lack of awareness and understanding of the relationship between data, information, and intelligence, as well as the role that collection, processing & exploitation, and analysis & production played in it.
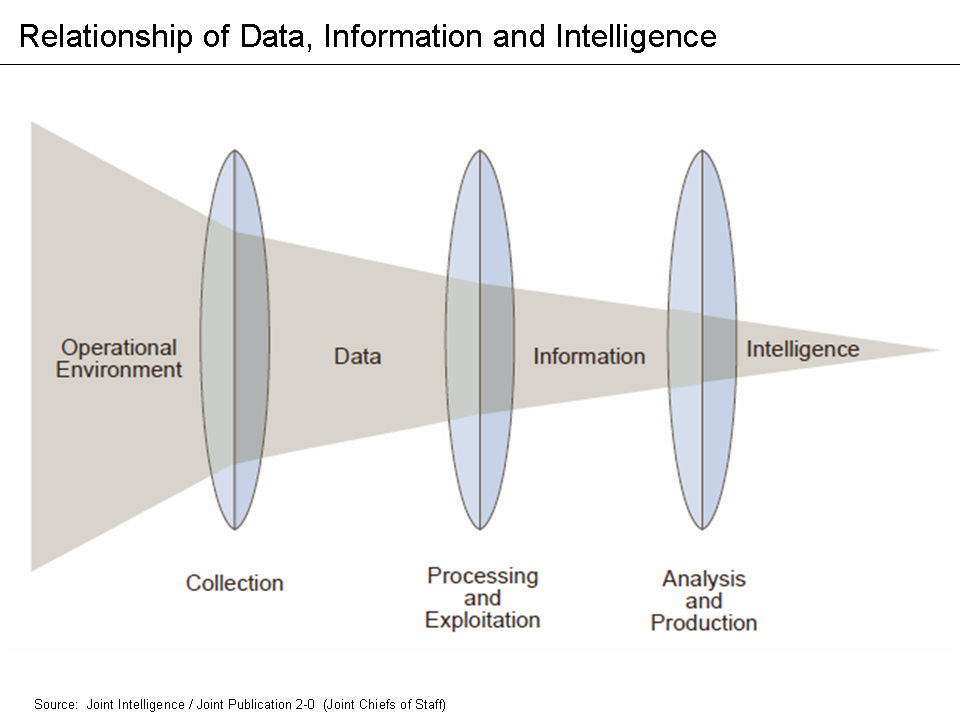
This, in my honest opinion, led many cybersecurity vendors to exploit customers with their business/operating model of “give us all your data and trust our black box to give you the answers.” Cybersecurity tools are a means of access to data and thus a potential collection source, BUT you should be selective about what data you collect in order to increase your probability of converting that into useful information and ultimately, intelligence. Otherwise, you risk data overload and the “garbage in, garbage out” problem. This leads to my second point…transparency and the ability to articulate the why and how you’re doing something builds confidence and trust. At Prae, we want to share why and how we’re helping others manage human risk, and a blog is one of many avenues to spread that message.
Now let’s examine the whisky making process:
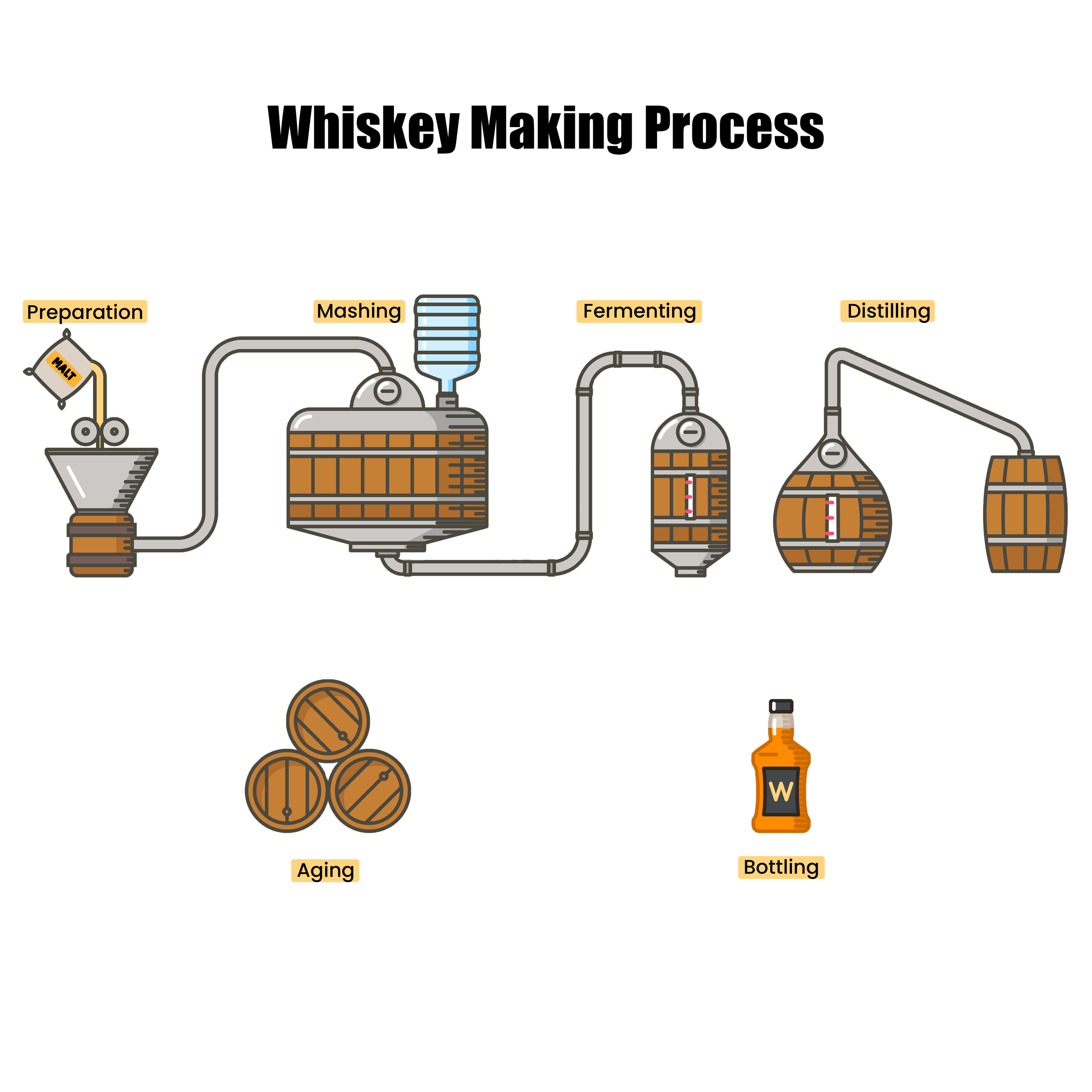
End-to-End Whisky Making Process
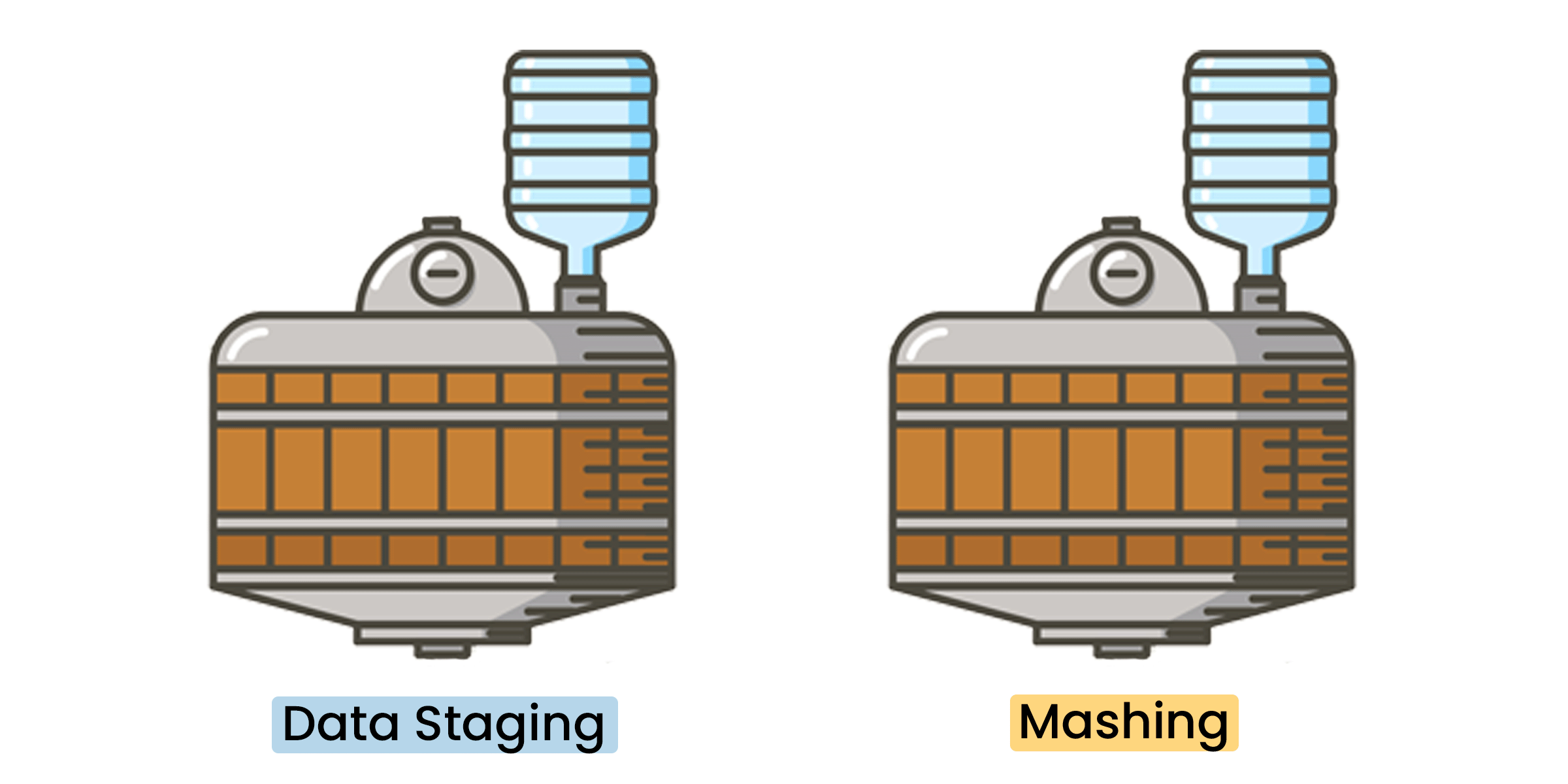
Much like data engineering, the preparation, mashing, fermenting, and distilling is a carefully orchestrated and precise process.
All whiskies have 3x core ingredients: water, grains/cereals, and yeast. On their own, each has its standard value and use, but process them together and you have the start of something more interesting. Grains/cereals and yeast are prepared and fermented into a “mash,” which provides its initial flavor profile and alcohol. The application of heating techniques to water initiates distillation.
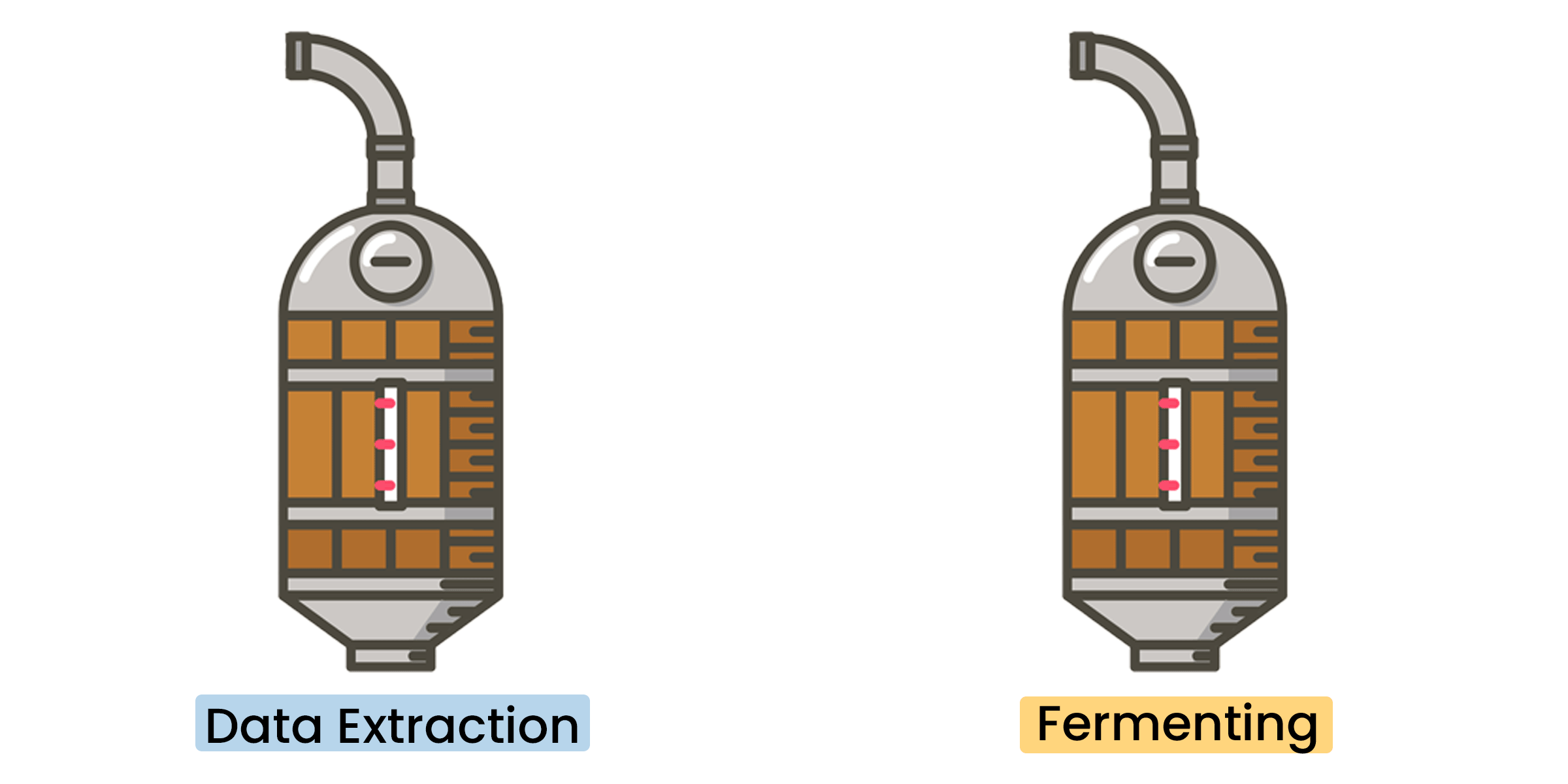
Distillation is the process of separating substances from a liquid through the conversion of liquid into vapor and condensation back to liquid. This process is typically performed in a still. Most whisky is made in either a pot/batch or column/continuous still (more on this below), where the shape, size, and material of the still influences the flavor. So, each time a whisky is heated to a vapor, condensed back into liquid, and collected…it’s a distillation. This first distillation is important because it separates substances in the fermented liquid as well as the alcohol. The condensed liquid that’s collected is now higher in alcoholic content (on average 20%) and referred to as “low wine.”
The collected low wine is distilled to increase the alcoholic content, but more importantly, to build flavor. Now it’s double distilled. Do it thrice and now it’s triple distilled. Since various substances in the liquid mixture will vaporize at different temperatures (173°F and 212°F for alcohol and water respectively), distillers can adjust the temperature and number of distillations to influence the initial flavor and alcohol by volume (ABV). This “high wine” will be subjected to wood-aging, which enriches the flavor and aroma (this will be discussed further in a future blog around whisky aging & blending and the art of data science).
Distillers are akin to data engineers as they monitor the distillate and orchestrate the “head,” “heart”, and “tail” for either redistillation or discarding. Similarly, data engineers are responsible for data collection, orchestration, and the Extract/Transform/Load or Extract/Load/Transform (ETL/ELT) process. They too are responsible for orchestrating what gets collected and what gets discarded. So, let’s take a look at the data-to-information process, but overlaid on top of the whisky making process:
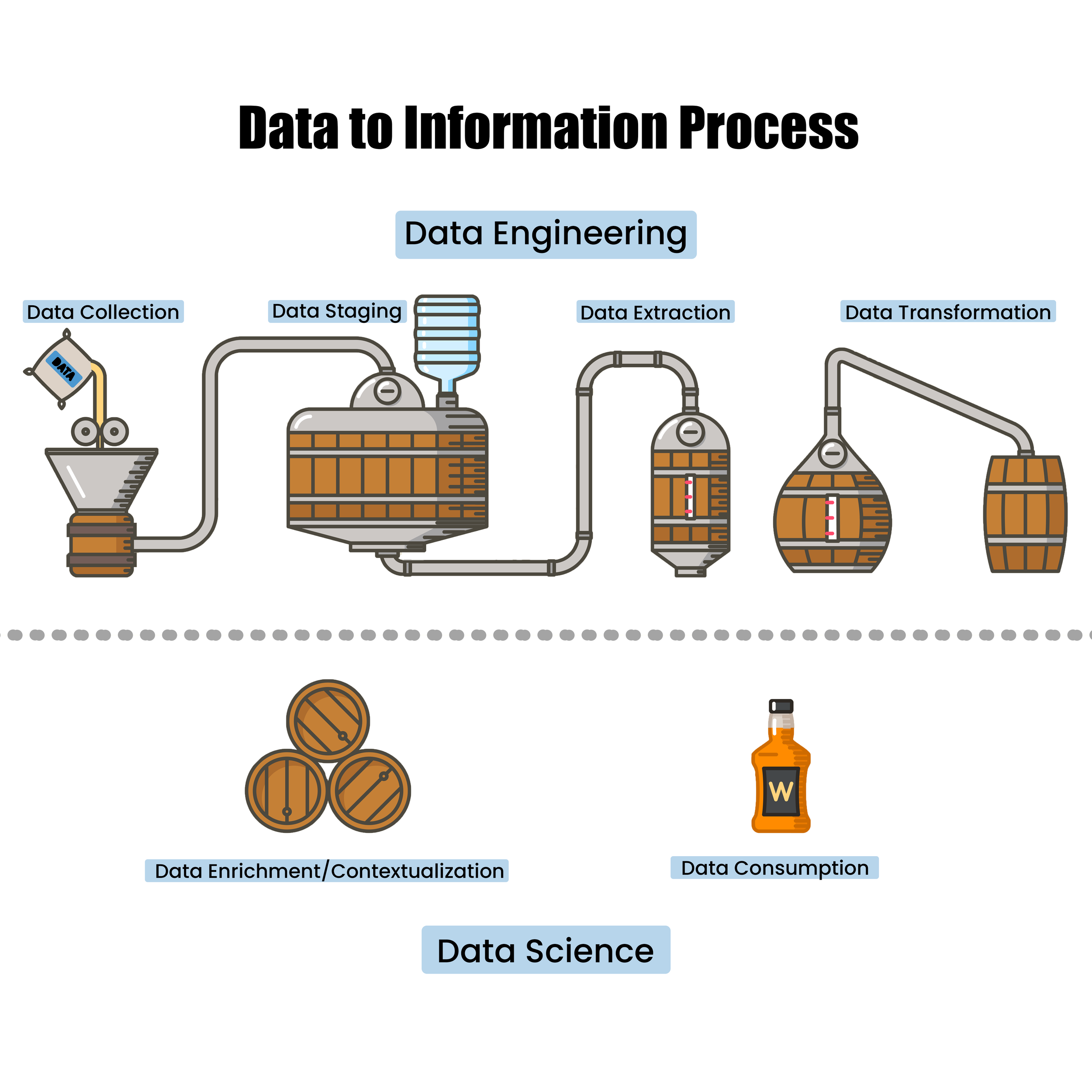
Data Engineering vs. Data ScienceThe preparation of core ingredients starts with the collection and staging of your data sources.
Simply defined, data is a raw observation. At a high-level, data can be structured, unstructured, and semi-structured.
Structured data is highly organized with standard formatting and generally stored in a database (e.g. SQL). This data can be categorized as quantitative and is easily accessed/interpreted by both humans and information systems/applications. On the flip-side, because this data is highly organized and formatted, one is often limited in their storage and use options.
Unstructured data is neither organized nor formatted in a predefined data model (e.g. NoSQL). As a result, this data cannot be easily accessed/interpreted by humans and/or information systems/applications. Unstructured data is categorized as qualitative and cannot be processed, stored, and analyzed with conventional tools and methods. While unstructured data requires a higher level of expertise/experience, it allows for greater flexibility in both storage and use options.
Semi-structured data is a hybrid between structured and unstructured where it lacks a predefined data model, but has some organization and formatting to it that makes it easier to store than unstructured data (e.g. json, xml, csv). This data relies on metadata (i.e. tags and semantic markers) to identify specific data characteristics and to scale data into records and/or preset fields; thus allowing this data to be better indexed, processed, and analyzed than unstructured data.
At Prae, we collect and process a diverse set of open-source (structured, unstructured, and semi-structured) data. Open-source data, much like raw whisky ingredients, can be accessed, used, and shared by anyone. However, it needs to be processed before it can be consumed by an analyst and interpreted for meaning. This is where ETL/ELT comes into play.
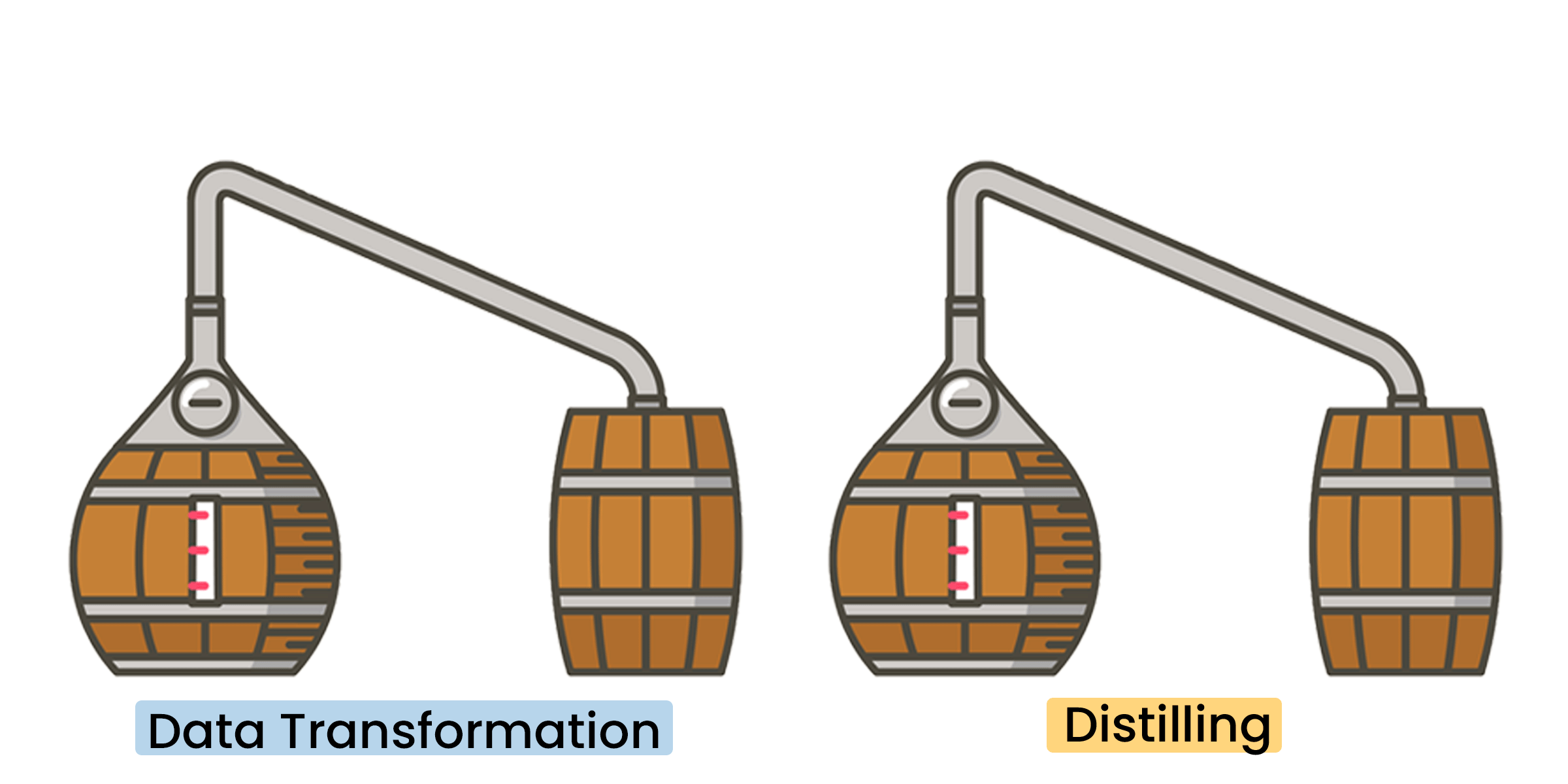
As previously mentioned, the shape, size, and material of the still influences the flavor. Pot stills are made of copper, which binds with the molecules of the liquid substances to enhance the distillate profile. As a result, in general, they will often retain the raw ingredient flavors and create a more robust distillate. On the flipside, they can only operate in batches as they have to be charged (aka filled), emptied, and cleaned in between each and every batch. To draw the parallel back to data engineering, this is batch processing where data is collected and stored for some period of time before it’s processed and analyzed.
Take a bunch of pot stills, stack them on top of each other, and you have a column still. Here the vapor passes up through the bottom of the column where it’s met by the wash, which is poured from the top. The wash falls back to the bottom and is converted back into vapor. Wash, rinse, repeat. Unlike pot stills, column stills can operate continuously because of this. It’s also worth noting that the column is typically packed with plates, which filter the substances and trap the different compounds between the plates. This is why it’s often referred to as “fractional distillation.” To draw the parallel back to data engineering, this is streaming processing where data is continuously processed and analyzed as it flows through and/or between systems. This is often performed in real-time or near real-time.
Here, we like the Apache Parquet and Databricks Delta formats as the storage part and Apache Spark and Databricks as the compute part. These flexible tools and formats allow us to store and process all of our open-source data regardless of format, and with Parquet or Delta, we get the added benefit of columnar storage and retrieval. This is specifically advantageous for more efficient storage (compression vs. decompression) and data throughput/performance like data skipping. Databricks also provides a web platform for Sparks with automated cluster management, IPython/Jupyter notebooks, and access to DeltaLake.
There are numerous technical challenges with figuring out what to extract versus what to filter/discard, selecting a data schema on which to standardize the transformation on, and loading that somewhere where analysts can further explore, exploit, and correlate things together. Creating a standardized datafile naming convention, up front, is an important, but oft overlooked task. As your collection, orchestration, and processing needs grow and change, the ability to quickly/efficiently scale and adapt (e.g. move, rename, etc) will depend on your datafile naming convention. We recommend using at least the date, source, and short descriptor separated by periods and/or underscores. Data, much like whisky ingredients, may undergo multiple distillations. Whisky distillation and data engineering are often iterative processes, where a consideration of initial inputs directly impacts the desired end result. Higher quality ingredients lead to higher quality products. With respect to data, the outcome of data engineering is information, which is a processed and structured form of data that can now be interpreted for meaning. And analyzed information is what produces intelligence.
So the next time you pour yourself a glass of whisky, remember these parallels and be more deliberate in your data collection, orchestration, processing, and naming as this will heavily determine your end result.